A year of performance breakthroughs, community growth, and the foundations being laid for CKAN's next chapter — as the project approaches its 20th anniversary.
Yoana Popova
02 Mar 2026
Share
Some software ages. CKAN has deepened.
Two decades after its first commit, CKAN quietly powers the data infrastructure of governments, research institutions, and humanitarian organisations on every continent. There are no billboards for that kind of success — only portals that stay up, datasets that load, and public servants who can do their jobs without thinking about what's running underneath.
2025 was the year the project leaned into that responsibility. Not with fanfare, but with the kind of focused, unglamorous work that good infrastructure demands: removing ceilings on what's possible at scale, rethinking the user experience from first principles, and laying the groundwork for the next generation of open data. Here's what the community built.
Performance that changes what's possible
For a long time, "CKAN at scale" came with asterisks. Large datasets were slow to download. Search pages felt sluggish. The experience was functional, but it wasn't fast enough to be invisible — and invisible is exactly what great infrastructure should be.
This year, the core team closed that gap.
⚡
15× faster large dataset downloads
CKAN 2.12 solves the large dataset download problem. A 13-million-record dataset that took 30 minutes — or timed out — now downloads in 2 minutes. This isn't a marginal improvement — it's the kind of change that makes big data feel fundamentally different to work with. For portals handling gigabyte-scale resources, the bottleneck is gone.
15×faster — 30 min (or timeout) down to 2 min for a 13-million-record dataset
🔍
30× faster search — without a frontend rewrite
Ian Ward's integration of HTMX means search pages now update only what's changed, rather than reloading the entire page on every filter. The result is a dramatically snappier experience that feels modern without requiring a ground-up rebuild. As Sergey Motornyuk put it:
30×faster search — incremental page updates via HTMX, no full reload
"By integrating HTMX for dynamic content refreshing, CKAN drastically reduces page reload times during search filtering, providing a smoother and faster user experience critical for large-scale portals." Sergey Motornyuk
🧠
Semantic search: finding data by meaning, not just keywords
Under Adrià Mercader's guidance, CKAN now applies machine learning to understand what users are actually looking for — not just matching terms, but interpreting intent. Someone searching for "carbon emissions by region" can surface the right dataset even if it's catalogued under different terminology. For non-technical users especially, this is a quiet revolution.
📁
File management rebuilt from the ground up
Led by Sergey Motornyuk, files are now first-class citizens in CKAN's architecture: versioned, storable across multiple cloud providers, and — crucially — resumable. If a large upload fails halfway through, users pick up exactly where they left off. For organisations handling large, sensitive, or time-critical data, that reliability changes what's possible.
🤖
Croissant support: open data ready for AI pipelines
CKAN now speaks the MLCommons Croissant standard, making datasets directly consumable by machine learning platforms including HuggingFace and Kaggle. As AI pipelines increasingly depend on open data, Croissant ensures that data published through CKAN arrives structured, documented, and ready to use — not a source of frustration for data scientists downstream.
🎨
CKAN 3.0: a UI built for flexibility, not just familiarity
Driven by Alex Gostev and the team, the 3.0 interface replaces the constraints of a single inherited design framework with something far more adaptable. Organisations can now tailor their portal's look and feel in ways that previously required deep custom development. It's a meaningful shift: from a platform with a fixed appearance, to one that genuinely fits the organisations using it.
A community that showed up
Open source lives or dies by the people who turn up. This year, CKAN turned up everywhere that mattered.
CKAN Table – Design 2
Event
Location
Highlights
UN Open Source Week
New York, USA
Joel Natividad and Dr. Nora Mattern presented on why digital public infrastructure needs open source. Read more
PyCon US 2025
Pittsburgh, USA
First-ever CKAN Open Space brought together users, developers, and partners. Read more
csv,conf,v9
Bologna, Italy
CKAN maintainers hosted an in-person workshop welcoming developers, policymakers, librarians, and civic leaders. Read more
OGP Global Summit
Vitoria-Gasteiz, Spain
Adrià Mercader and Andrew Nette discussed CKAN's role in global open government. Read more
Canadian Open Data Summit
Fredericton, Canada
Steven De Costa, Ian Ward, and Lex du Plessis connected with Canada's open data community.
These weren't just appearances. They were signals that CKAN's community is active, engaged, and present in the rooms where open data policy gets made.
Building for the long term
The most important work this year wasn't in the codebase — it was in the structures that will keep CKAN healthy for the next decade.
🌱
The POSE II Project
The POSE II Project, funded by the National Science Foundation, brought Jamaica Jones on board as Community Manager and launched a series of Community Listening Sessions. What emerged wasn't just feedback — it was a clearer picture of who CKAN's community actually is, what they need, and how the project can serve them better.
The sessions directly shaped a contributor's guide, storytelling workshops, and the programming now being planned around CKAN's 20th anniversary. An ecosystem catalog is underway, designed to make visible the full range of ways CKAN is being used worldwide.
The CKAN Steering Committee took shape this year, developed through the POSE II process. This isn't a committee in the bureaucratic sense — it's a group of core stakeholders with real investment in CKAN's direction, working through a sustainability planning process. For a project embedded in critical public infrastructure, this kind of governance matters. It's how you ensure that decisions are made by people accountable to the communities that depend on the software.
🎙️
CKAN Monthly Live
CKAN Monthly Live led by Yoana Popova, continued to be the project's living room — monthly webinars where the community shares what they're building and what they're learning. This year's sessions covered everything from humanitarian data coordination to sustainable transport to economic development.
Building a global knowledge base for low-emission mobility data, set to launch at COP30. CKAN is the foundation for an initiative with genuine planetary stakes.
Using CKAN to surface knowledge across Latin America and the Caribbean — connecting researchers, policymakers, and citizens to data that was previously hard to find.
Migrated from a legacy system to a modern, scalable CKAN-based platform — preserving years of scientific data while making it significantly more accessible to researchers.
CKAN's 20th anniversary arrives in 2026. That's a rare milestone for any software project, rarer still for one that remains genuinely central to how open data works in the world.
The question the community is sitting with isn't whether CKAN works — that's been answered, repeatedly, at scale, in production environments that can't afford failure. The question is how CKAN evolves without losing the qualities that made it worth deploying in the first place: reliability, openness, and a deep commitment to the public good.
2026 is an opportunity to articulate what CKAN stands for — not as a marketing exercise, but as a genuine reckoning with what two decades of open data infrastructure have taught the project, and what the world now needs from it.
The road ahead isn't about growth for its own sake. It's about remaining useful, trustworthy, and open — so that the institutions doing the hard work of governing well, responding to crises, and advancing knowledge can keep doing it on foundations they trust.
Thank you
None of this happens without people.
⚙️
Core Technical Team
Ian Ward, Adrià Mercader, and Sergey Motornyuk led the year's most significant technical work, on performance, search, and file management respectively. Their expertise and commitment to the project's long-term health is evident in every release.
🤝
Community Contributors
Yan Rudenko, Oleksandr Cherniavski, Tome Cirun, Carl Antuar, William Dutton, Jesse Vickery, and the many others who submitted pull requests, filed bugs, improved documentation, and answered questions in forums. Open source is the sum of these contributions.
🎨
UI Revamp Team
Alex Green for doing the hard work of rebuilding CKAN's interface, and Alex Gostev for holding the product vision of the CKAN 3.0 Taskforce.
Datopian and Link Digital for their continued investment in the project's technical and community health.
📖
Open Knowledge Foundation
OKF for holding CKAN's assets in trust and championing the open governance model that keeps the project independent and credible.
🌍
Global User Community
The organisations who presented at CKAN Monthly Live, shared their use cases openly, and trusted CKAN with infrastructure that matters. You're the reason this work continues.
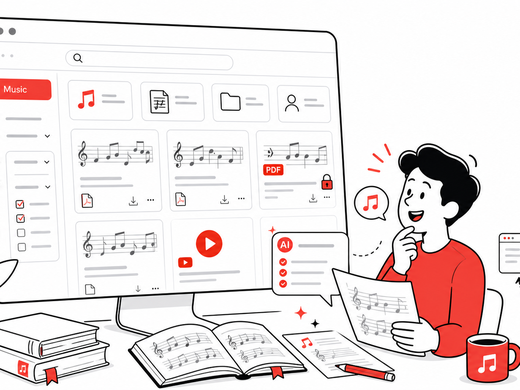
Wolfgang from Ondics built an open source sheet music catalog on CKAN — with AI metadata generation, YouTube playback, and cross-instance sharing. Here's how.
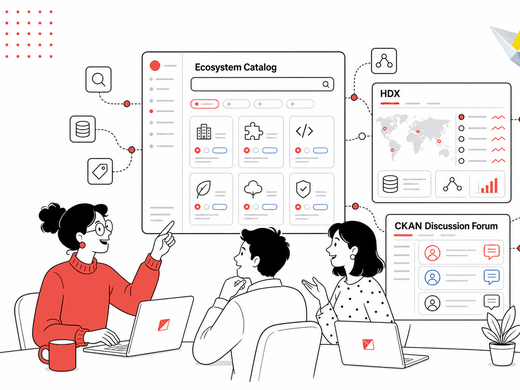
A recap of what the CKAN community covered on June 17, 2026: a live demo of the new CKAN Ecosystem Catalog, a deep-dive into HDX Tabular Data Endpoints, the launch of the new community discussion forum — and, surprise surprise, a very unexpected use of CKAN as a sheet music directory with AI-assisted metadata. Yes, really.